STM32CUBEMX是意法半导体推出的一款图形化配置工具,可以通过图形化点击的方式配置STM32芯片的各种硬件外设、部分软件组件。
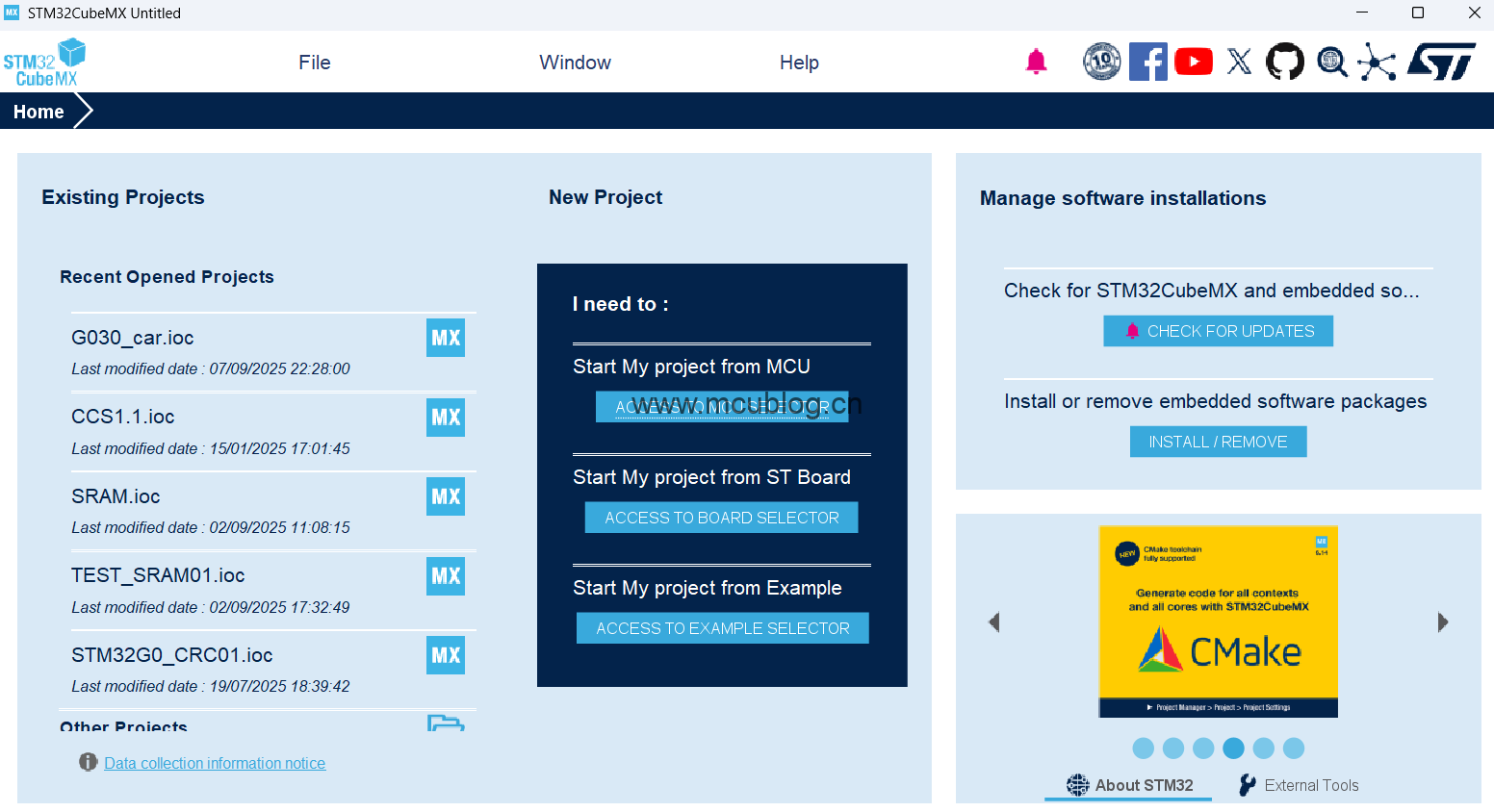
经常使用的童鞋,肯定会发现一个现象,就是它生成的Keil工程,优化等级默认是O3,这是为什么?
其实这样做的主要目的,是为了在嵌入式这种资源受限的处理器场景下,保证程序能正常运行。
说人话!
意法半导体的HAL库,体积庞大,及其占用空间。随便写写,编译之后就占用了好几KB的flash。直到后面推出了高效、简介的LL库,这个现象才相对好一些。 像我之前写过一些HAL库的教程,STM32CUBEMX_定时器控制LED闪烁,STM32CUBEMX_按键检测_按键控制LED等,都使用了HAL库,占用空间很大。
我们可以先看一下这个工程,使用O0的优化级别,也就是不优化。芯片是STM32G030F6,自身flash为32KB,ram是8KB。
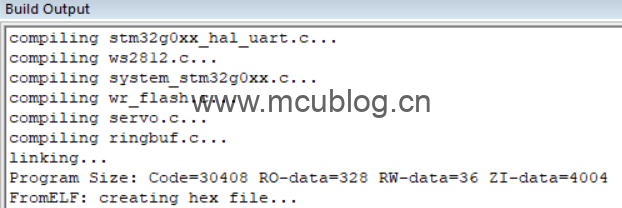
编译后,flash占用大小为30408+328字节,也就是30736字节,几乎快用完了!
还是这个工程,使用O3优化等级,重新编译:
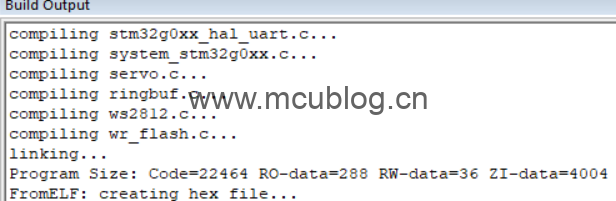
编译后,flash占用大小为22464+288字节,也就是22752字节。相比之前,少了7984字节,将近8KB。
表面看起来,不同的优化等级最直接的效果就是节省flash空间。那么,还有别的好处吗?
简单搜了一下,主要有以下几方面:
1、优化flash占用空间,不解释;
2、提升CPU执行效率
循环深度优化,把部分for/while这类循环展开,改为连续的代码,减少循环的逻辑判断部分,优化执行效率。
指令重排,对指令执行顺序进行重新排列,尽量减少出现流水线“空等”的情况。
那么,优化会带来什么问题?
最直接的现象就是:调试困难。
经常调试的朋友肯定知道,如果直接在O3优化等级的Keil工程中,开启在线仿真,会出现一个很奇怪的现象。即,单步执行时,程序指针经常不会按照你编写的代码顺序执行。在一定范围内,跳来跳去,看起来很没有规律,我自己也确实找不到规律。
这就是前面说的,由于O3等级的优化,导致指令重新排布、部分循环展开等等,光标会跳过某些代码行,或者跳来跳去。
怎么办?
其实也很简单,在线仿真的时候,优化等级修改为O0。仿真没问题后,优化等级修改为O3。如果能接收O0,也可以保持,不改为O3。
所以,简单来说,不同的优化等级,对应不同的资源占用方案。但是程序执行效果上,两者是一样的,额,应该是一样的吧~~~
我是单片机爱好者-MCU起航,打完手工!